What is Cross Site Scripting
Cross site scripting (XSS) is the name for a collection of attacks that involve an attacker getting your application to output arbitrary data for a client to interpret. This can be done for many different purposes, such as defacing a website for advertising, overlaying custom HTML / CSS rules to override your own, or for more evil purposes such as executing arbitrary Javascript code on a site. For AJAX
The simplest possible example of this is shown below. An attacker can simply put in <script type="text/javascript">alert("xss possible");</script> to the query string parameter someVariable and see that they can successfully cause a SQL injection attack. A more advanced form of this would be if you stored user data in a database, and printed it out without concern for possibly embedded HTML elements. An attacker could very simply put any arbitrary HTML, CSS, or Javascript they want into the application!
Simple .NET XSS Vulnerability
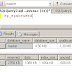
|
Response.Write(Request.QueryString["someVariable"]); |
A typical attack might look like this:
1. An attacker finds an XSS vulnerability, and types in some arbitrary HTML.
2. At the same time, he identifies the address location of the method used to change passwords on your system.
3. The attacker writes a Javascript that calls this change password method to change the password of the current logged in user to a known quantity, "password".
4. The attacker injects a small Javascript tag as input for some field or query string parameter that will be printed out for other users who are already logged in to the system: <script type="text/javascript">changePassword("password");</script>
5. A random user comes along and views the page that prints out the data the attacker provided, and as the script is on your domain, cross domain rules built into the browser don't catch the attack, and the code is executed automatically.
6. Now the random user who just happened to view this page has had their password reset to a new value without ever being the wiser.
You see this sort of thing happen a lot on Facebook. Sometimes they don't even have to have a vulnerability present in your system, but use a more basic approach: telling a user "If you copy and paste this into the address bar on Facebook, everything turns upside down", or something similar. It's very hard to protect against users doing silly things, of course, but the basic principal is the same there, they just trick the user into doing it to themselves.
The (Old) Fix
Microsoft originally included an input validation filter in ASP.NET called Request Validation. Essentially, it worked as a filter for any request coming into the application to check for any data that looked like it could be an attack (usually Javascript tags), and if found, terminated the request with an error. Of course, that completely blocks out people who WANT a user to be able to submit HTML stuff as well. This is turned on by default in the Machine.config (The global machine Web.config default settings), or you can turn it on or off manually in the Web.config file.
Turning on Request Validation Globally
|
... <system.web> <pages buffer="true" validateRequest="true" /> ... |
This type of input filtering is really limiting, but it can be an ok first line filter if you never want users to submit HTML in your application. It is not a global solution to the issue, but again, as a first line defense it's available for your use. I tend to turn it off and rely solely on output encoding (the next fix).
The Fix
The fix is fairly simple for something like this: encode anything that comes from an untrusted source (user data). Encoding means turning a string like <script type="text/javascript">alert("xss possible");</script> into <script type="text/javascript">alert("xss possible");</script>. This defeats XSS attacks by stopping the browser from interpreting the code, but rather print it out as if it were plain text. ASP.NET provides a very simple methodology for this: The HttpServerUtility.HtmlEncode() method. When any string is wrapped by this method, it converts said string into a safely HTML encoded variant instead... kind of...
HttpServerUtility.HtmlEncode example
|
var safeString = HttpServerUtility.HtmlEncode(Request.QueryString["someVariable"]); |
The reason I say "kind of" is because this method is flawed. The above method will indeed encode our simple example, but it is based on a black list of characters instead of a white list, which means it suffers from possible encoding attacks (where I encode my HTML code as Japanese, or some other language), and other methods of circumvention.
Black Lists vs White Lists
The difference between a black list and a white list is simple: A black list specifies only the things which aren't allowed, and a white list specifies only the things that are allowed. White lists are inherently stronger in every case where you are parsing arbitrary strings for validity because if an attacker comes up with some new way to circumvent a black list, the black list has to be updated, but in a white list the only things ever allowed through are the things that are specified. Remember this for later when looking at data validation methodologies as well, as it applies there.
If HttpServerUtility.HtmlEncode() is flawed, what should you use? The Microsoft AntiXSS Library. This library does the exact same thing as the aforementioned HttpServerUtility.HtmlEncode() method, along with several other handy things, and the best part is, it is a white list based solution. In fact, it is such a better solution, that it has become a core piece of .NET 4.5, though it still requires configuration to set it to be used by default over the regular HttpServerUtility.HtmlEncode() methods.
AntiXSS Library Usage
For the most part, the AntiXSS Library is used the same way as the HttpServerUtility.HtmlEncode() method. Setting everything up to use the AntiXSS Library gets a little bit more involved though.
If using ASP.NET 4.5, a simple configuration change in the Web.config file is all that's needed, and any method using the built in encoding methods will take advantage of the new built-in AntiXSS methods instead of the original encoder:
ASP.NET 4.5 AntiXSS setup
|
<httpRuntime ... encoderType="System.Web.Security.AntiXss.AntiXssEncoder, System.Web, Version=4.0.0.0, Culture=neutral, PublicKeyToken=b03f5f7f11d50a3a" /> |
As most of us aren't quite there yet though, we need to get a little more creative. If you are lucky enough to be working on ASP.NET 4.0, you can use this method to register your own custom encoder class as the default encoder for the application and do essentially the same thing, it just requires adding a reference to the AntiXSSLibrary in your application.
First, you add the reference to the project in VisualStudio for the AntiXSSLibrary, after downloading it from here. Then, we have to create a class that inherits from System.Web.Util.HttpEncoder, which can be set to be used as the default encoder for the system.
Custom AntiXSS HttpEncoder Class
|
using System; using System.IO; using System.Web.Util; using Microsoft.Security.Application; public class AntiXssEncoder : HttpEncoder { public AntiXssEncoder() { } protected override void HtmlEncode(string value, TextWriter output) { output.Write(AntiXss.HtmlEncode(value)); } protected override void HtmlAttributeEncode(string value, TextWriter output) { output.Write(AntiXss.HtmlAttributeEncode(value)); } protected override void HtmlDecode(string value, TextWriter output) { base.HtmlDecode(value, output); } ... } |
This example is pretty basic, and there are several other methods that can be implemented. I recommend reading this article, which is where this class is largely from. There is also a more complete example available there.
One other best practice that I use here is to abstract the encoder with a wrapper class, just in case Microsoft fixes this and makes the AntiXss encoding methods standard at a later point and we can switch back to the default encoder. The reason I do this is because inevitably there will be other places in the interface where the project will need to call the AntiXssLibrary methods to encode things manually, and it's usually a good idea to centralize this dependency (This is the idea of "loose coupling" so that your own code is only ever reliant on your own interfaces instead of third party interfaces that might change). A very simple example class I usually use is below, which essentially wraps all of the AntiXssLibrary methods for now.
Example Encoder Abstraction Class
|
namespace GenericApplicationFramework.UI.MVC.Security { public static class Encoder { public static string HtmlEncode(string value) { return Microsoft.Security.Application.Encoder.HtmlEncode(value); } public static string HtmlAttributeEncode(string value) { return Microsoft.Security.Application.Encoder.HtmlAttributeEncode(value); } public static string JavaScriptEncode(string value) { return Microsoft.Security.Application.Encoder.JavaScriptEncode(value); } public static string LdapDistinguishedNameEncode(string value) { return Microsoft.Security.Application.Encoder.LdapDistinguishedNameEncode(value); } public static string LdapFilterEncode(string value) { return Microsoft.Security.Application.Encoder.LdapFilterEncode(value); } public static string UrlEncode(string value) { return Microsoft.Security.Application.Encoder.UrlEncode(value); } public static string XmlEncode(string value) { return Microsoft.Security.Application.Encoder.XmlEncode(value); } public static string XmlAttributeEncode(string value) { return Microsoft.Security.Application.Encoder.XmlAttributeEncode(value); } } } |
A simple Web.config change configures our project to use this class instead of the default encoder for the system.
ASP.NET 4.0 AntiXSS setup
|
... <system.web> <httpRuntime encoderType="AntiXssEncoder, YourProjectAssemblyName"/> ... |
Finally, if you are using an older version of .NET prior to 4.0, you will have to manually call these methods in your code. I still recommend using a wrapping class like above if you end up doing that. If something changes and you need to change the encoding methods, you can do it in one place instead of doing a find and replace across the application.
ASP.NET 4's New <%: ... %> Syntax
As of MVC2 and ASP.NET 4, there is a new ASPX syntax that encodes output automatically. This means that instead of having to write something like this:
Old Syntax Example
|
<%= AntiXSSEncoder.HtmlEncode(SomeVariable) %> |
You can simply write this:
New Syntax Example
|
<%: SomeVariable %> |
This will automatically pass the content of SomeVariable through the default encoder for the project. If using the above methodologies for setting up the AntiXSSLibrary as the default encoder, this will automatically make those two code blocks equivalent. This handy shortcut should give everyone another reason to want to move to ASP.NET 4.
The Razor ViewEngine in MVC3 does this automatically for output by default.
The Input vs Output Encoding Debate
There has been a very long debate going on in the community about whether user submitted data should be encoded on input before being stored, or on output. I think the above new syntax sort of shows that Microsoft has sort of given it's blessing to the latter over the former, but just for posterity's sake, I want to discuss why I feel this is the right choice.
When a user enters data, they expect it always be the same when they look at it later. If a program automatically changed what you typed to be helpful, it would get quite annoying very quickly (think of how Word automatically changes quotes and other symbols for you as you type. If you're a developer, you will eventually have to deal with someone wanting to copy and paste from Word, and you will run into this behavior). As such, I feel that user data should be stored as entered unless there is a really good reason for doing otherwise.
The other reason I feel this is the right choice, is the question of what encoding is the right one to store data in? If you are writing a web app, the typical answer is HTML Encoded, but what if that web app also has to send out e-mails with user data in them? Now you have to unencode the data for usage there. Encoding is an output issue.
The counter argument is that you take a small performance hit when you encode on every output vs. on input where you only take that hit once. This is a very real concern to take into consideration if you have a very large system with thousands of concurrent users and you need to squeeze every ounce of performance out of your system... There are two issues here that I see though. First, you probably aren't writing the next Facebook or YouTube where this will be a concern, and if you are, you probably have other issues that will hit you harder first. And second, throwing extra hardware at the problem may in fact be cheaper at that point anyway. Still, it is a point to take into consideration.
Filtered HTML
When you want your users to be able to submit HTML content, things get trickier. The AntiXSSLibrary supplies a method called GetSafeHtmlFragment, which you can use to only escape the "dangerous" content of a given string, but if you are automatically encoding all output, it means you have to be a little careful, and fallback to manually calling the right encoding method for these outputs. ASP.NET 4 also introduced the IHtmlString interface (and HtmlString concrete class) for this purpose, as any string of this type will not be automatically encoded.
Safe HTML Encoding on Output ASPX
|
<%: new HtmlString(AntiXSSLibrary.GetSafeHtmlFragment("<h1>Safe HTML</h1>")) %> |
The Razor view engine for MVC3 has a similar but distinct syntax for this.
Safe HTML Encoding on Output Razor
|
@Html.Raw(AntiXSSLibrary.GetSafeHtmlFragment("<h1>Safe HTML</h1>")) |
Conclusion
The rule here is always encode any data that originated from an untrusted source. Usually, we mean user data here, but you can take this to its logical conclusion: any data that is not generated in system should be encoded, including any data that originates from a semi-trusted data store like a file system or database, as an attacker can just as easily poison those via another vector. As such, I'd say that in any ASP.NET application it is in your best interest to make sure you are encoding all output by default. ASP.NET 4 gives us an awesome, automatic way of doing this, and if you are lucky enough to be there, you should absolutely be using it.
Also, always use the AntiXSSLibrary over the HttpServerUtility.HtmlEncode() methods. A white list solution will always be preferred. One quick caveat I found with MVC3 and below though, the textarea helper adds an extra newline to content when using the AntiXSSLibrary. This is fixed in MVC4, but for now, a simple solution is to use Javascript to remove this newline on page load
MVC3 Textarea Javascript Fix
|
$("textarea").each(function () { $(this).val($.trim($(this).val())); }); |